

Versuch einer Erklärung des Vorgehens, einer Modellbildung und der Unterschiede
Definition Black-Box
Black-Box, übersetzt schwarzer Kasten, ist ein Modell je nach Themengebiet z.B. technischer oder psychologischer Art, in dem sowohl die Eingabe (input) als auch die Ausgabe (output) bekannt sind, nicht aber die technischen bzw. kognitiven Prozesse (bei unseren zwei Beispielarten), die “innerhalb” der Black-Box ablaufen. Sprich es lassen sich keine Beziehungen zwischen Eingang und Ausgang, oder Ursache und Wirkung definieren.
Definition White-Box
White-Box auch ab und an Glass-Box genannt, ist genau genommen vereinfacht das Gegenteil einer Black-Box. Es sind neben den Eingangs. und Ausgangsparametern alle System internen (in der Box) ablaufenden Prozesse, relevante Merkmale relevant. z.B. bei der Softwaretestung ist der Quell-Code z.b. bekannt, und es lassen sich idealerweise 1-1 Beziehungen zwischen Ursache und Wirkung setzen.
Mischmodell Grey-Box
Die Grey-Box ist quasi die ehrlicherweise und der Einfachheit halber meist als Black-Box bezeichnet er Normalfall, weil immer eine Vereinfachung eines Systems und keine 100% mathematische Sicherheit ein System vollständig beschrieben zu haben vorliegt. Sei es aus wirtschaftlichen oder physikalischen Gründen.
Erklärungsansätze aus der Informatik
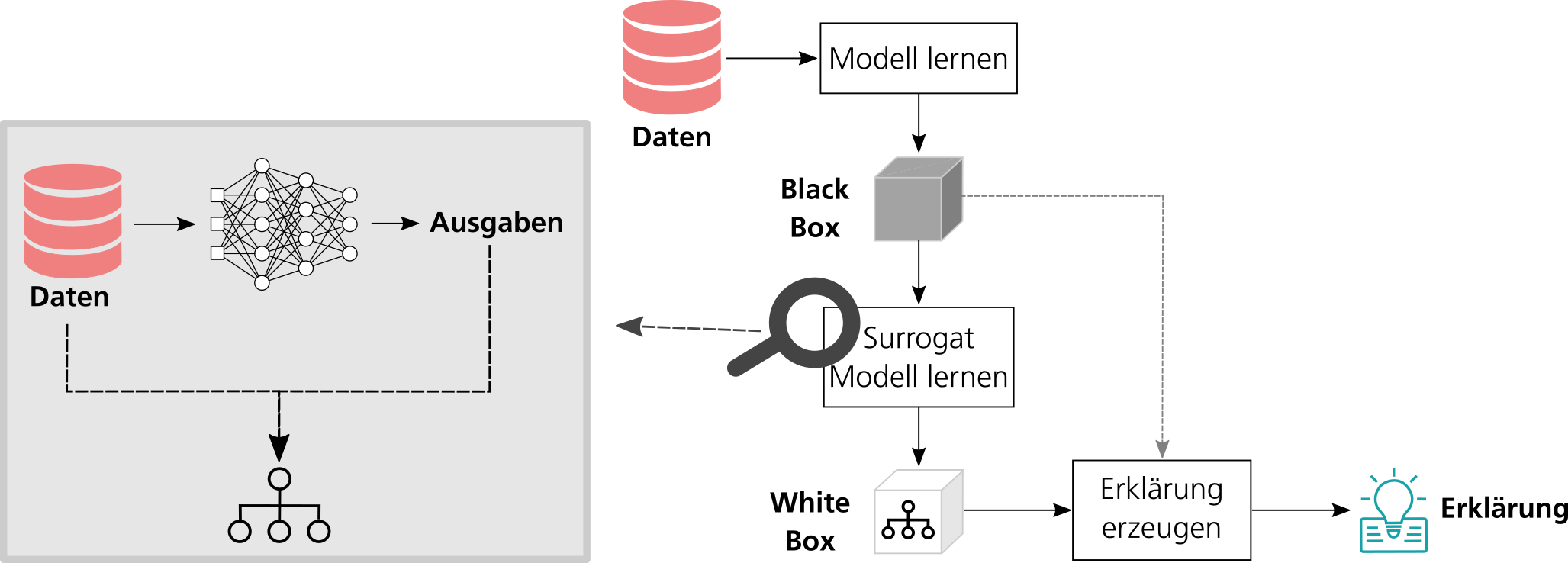
Eine Möglichkeit, ein Black-Box-Modell global zu erklären, ist die Abbildung des Modells mittels eines White-Box-Modells. Hierfür wird aus dem Black-Box-Modell ein interpretierbares Stellvertretermodell – auch als Surrogat bezeichnet – extrahiert. Dieses ist dann nutzbar, um Erklärungen zu erzeugen.
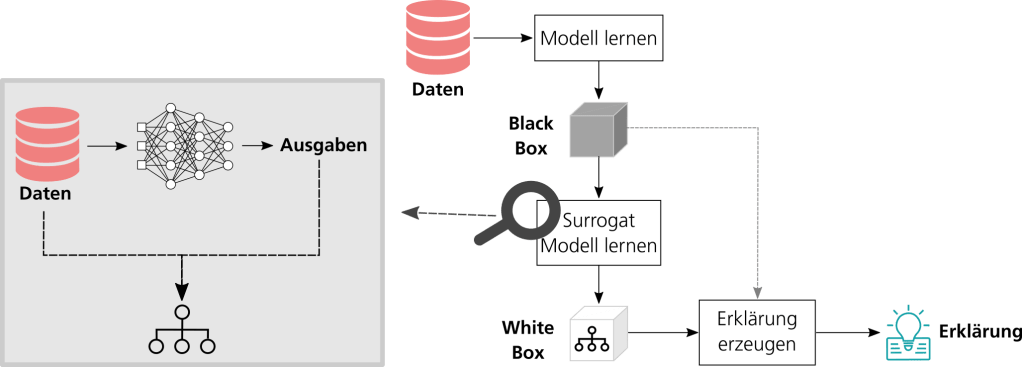
Abbildung 1: Von der Black Box zur Erklärung: Extraktion von White-Box-Modellen aus Black-Box-Modellen. Quelle: Nina Schaaf.
Konkret funktioniert die Extraktion eines Surrogats (zum Beispiel eines Entscheidungsbaums) aus einem Black-Box-Modell wie in Abb. 1 dargestellt. Zuerst wird unter Zuhilfenahme des Black-Box-Modells für alle Eingabedaten, bestehend aus Merkmalen und einer Sollausgabe, eine Vorhersage berechnet (links). Im Anschluss werden die Eingabemerkmale zusammen mit der Vorhersage des Black-Box-Modells dazu verwendet, das Stellvertretermodell zu trainieren (rechts). Dieser Ansatz eignet sich besonders gut für die Arbeit mit tabellarischen Daten. Für Bilddaten bietet sich hingegen beispielsweise die Verwendung von Konzepten an, die tiefe neuronale Netze erklären (Ghorbani et al. 2019). Hierbei werden automatisch visuelle Konzepte identifiziert, die für das Black-Box-Modell besonders wichtig waren. Abb. 2 zeigt das Beispiel eines Reifen-Konzepts, das für die Klasse „Polizeitransporter“ besonders relevant ist. Das Reifen-Konzept befindet sich in vielen Bildern von Polizeitransportern – unabhängig von ihren sonstigen Merkmalen wie Farben und Beschriftungen – und bildet deshalb ein zentrales Erkennungsmerkmal für diese Klasse.

Abbildung 2: Erklärung eines Convolutional Neural Networks über visuelle Konzepte. Oben: Reifenkonzepte als Erklärung der Klasse „Polizeitransporter“. Unten: verschiedene Bilder von Polizeitransportern, die alle das Reifenkonzept beinhalten (orangene Umrandung). Quelle: Ghorbani et al. 2019.
Während globale Erklärbarkeit vor allem für Modellentwickler wichtig ist, sind für den Endanwender häufig nur die Erklärungen einzelner Entscheidungen relevant. Setzt eine Bank beispielsweise ein Kreditvergabesystem ein, das auf ML-Methoden aufbaut, muss dieses System einem Kunden erklären können, welche Punkte seines Kreditantrages zu einer Ablehnung geführt haben. Denn sind Nutzer von einer solchen algorithmisch getroffenen Entscheidung betroffen, so müssen laut DSGVO dem Anwender aussagekräftige Informationen über die involvierte Logik bereitgestellt werden (European Parliament 2016).
Für lokale Erklärungen wird meist die Wichtigkeit der Eingabeattribute angegeben, die zu einer bestimmten Entscheidung geführt haben. Dieses Konzept lässt sich auch auf Probleme aus der Bildverarbeitung übertragen. Hier wird dann beispielsweise jedem Pixel ein positiver oder negativer Wert zugeordnet, je nachdem, ob dieser die letztendliche Entscheidung des ML-Modells begünstigt hat oder nicht (siehe Abb. 3). Eine populäre Methode, die für tabellarische Daten, Bilddaten und Texte angewandt werden kann ist LIME (Ribeiro et al. 2016). LIME verfolgt eine perturbationsbasierte Erklärungsstrategie. Das bedeutet, dass Teile der zu erklärenden Dateninstanz (zum Beispiel ein Bild) gezielt verändert und die Auswirkung dieser Veränderung auf die Modellvorhersage untersucht werden. Die Anwendungsfelder für lokale Erklärungsansätze sind vielfältig und reichen von medizinischen Anwendungen über die Qualitätsanalyse bis hin zum autonomen Fahren.

Abbildung 3: Erklärung der Klasse »Schwarzer Schwan« für das vorliegende Bild mithilfe der Methode LIME. Das Hauptmerkmal für diese Klasse ist der rote Schnabel. Quelle: https://images.app.goo.gl/NSmc6JEnzbr4b7tC7
Quelle Bsp.: ww.dgq.de
Verwandte Beiträge

Grundbegriffe zum DoE
Basiswissen rund um die statistische Versuchsplanung, und ein paar Beispiele Folgende Begriffe werden für die Vereinfachung der Verständlichkeit an Hand…

Arten der Modellbildung bei DoE
Man unterscheidet zwei verschiedene Wege der Modellbildung sowie Mischformen Physikalische Modellbildung (White Box) Die physikalische Modellbildung (auch white- oder glass-box…

{kind=link}
{kind=link}
{kind=link}
Hinterlasse einen Kommentar